Building recommendation systems with Neo4j

How to build a recommendation system with Neo4j
Ready to create Netflix-style recommendations that actually work? Learn how to build, optimize, and deploy smart suggestion systems with Neo4j, from basic graphs to production-ready features.
Modern applications now rely on recommendation systems to power personalized suggestions that enhance user experiences. Companies like Netflix, Amazon, and Spotify have demonstrated the tremendous value of well-implemented recommendation engines, with Netflix estimating that its recommendation system saves it $1 billion annually in customer retention costs. In this article, we'll explore how to use Neo4j, a leading graph database, to create a simple yet effective recommendation system.
Understanding recommendation systems
A recommendation system is designed to filter information and suggest items or content to the end user. These systems typically fall into three main categories:
Collaborative filtering
This approach analyzes user behavior patterns to suggest items that similar users have enjoyed. You've likely seen this in action with messages like 'Customers who bought this also bought...' recommendations, which leverage collective user preferences to make predictions.
Content-based filtering
This method focuses on item characteristics rather than user behavior, matching products based on their inherent features and attributes. Netflix's 'Similar movies to what you've watched' feature is a prime example of content-based filtering in action.
Hybrid approaches
Modern systems combine collaborative and content-based filtering for more sophisticated recommendations. Spotify's Discover Weekly exemplifies this approach, using both listening history and song attributes to create personalized playlists that feel both familiar and fresh. The main objective is to offer tailored suggestions based on user preferences, interests, or past behaviors. These systems are widely used across various business domains, such as social media, e-commerce, and entertainment, playing a crucial role in personalizing user experiences and boosting customer satisfaction.
Social networks
In social media, recommendation systems are vital for enhancing user engagement and content discovery. By collecting information like hashtags, posts, and user relations, these systems help users find more relevant posts, articles, videos, or new friends.
E-commerce
In e-commerce, recommendation systems are essential for improving customer satisfaction and boosting revenue. They define highly personalized product suggestions based on user preferences, purchase history, and browsing history, encouraging cross-selling and upselling.
Understanding Neo4j and graph databases
Neo4j is a graph database management system optimized for handling connected data. Unlike traditional relational databases, Neo4j's native graph storage provides unique advantages for building efficient recommendation systems.
Key components
Neo4j's foundation rests on nodes and relationships. Nodes represent entities like users or products, storing properties as key-value pairs and carrying multiple labels for categorization. Relationships connect these nodes directionally and can also carry properties - for example, a "PURCHASED" relationship might include timestamp and price data.
Performance benefits
The database's architecture uses index-free adjacency, meaning relationships are physical connections rather than database joins. This enables constant-time traversal between nodes, making complex queries significantly faster than traditional databases. Neo4j's native graph processing optimizes pattern matching and graph algorithms, essential features for recommendation systems.
If you like hands-on AI projects, don’t miss AI expense tracker: when banks fall short - a real-world example of data classification powered by OpenAI.
Understanding Neo4j and graph databases
Neo4j is a graph database management system optimized for handling connected data. Unlike traditional relational databases, Neo4j's native graph storage provides unique advantages for building efficient recommendation systems.
Key components
Neo4j's foundation rests on nodes and relationships. Nodes represent entities like users or products, storing properties as key-value pairs and carrying multiple labels for categorization. Relationships connect these nodes directionally and can also carry properties – for example, a "PURCHASED" relationship might include timestamp and price data.
Performance benefits
The database's architecture uses index-free adjacency, meaning relationships are physical connections rather than database joins. This enables constant-time traversal between nodes, making complex queries significantly faster than traditional databases. Neo4j's native graph processing optimizes pattern matching and graph algorithms, essential features for recommendation systems.
Cypher Query Language
Cypher is a query language similar to SQL, used for creating, browsing, and updating information in the graph database. It allows for highly optimal operations on the database.
# Create Node
CREATE (node:label{key_1:value, key_2:value ...)
# Matching by nodes
MATCH (node:label)
RETURN node
# Matching by relationship
MATCH (node:label)<-[: Relationship]-(n)
RETURN n
Building a recommendation system using Neo4j
Let’s build a simple system recommending movies based on what users have watched. The system will allow the creation of relationships between the User and the Movie. Users should also be able to follow other users. The goal is to display movies watched by followed users.
Build our graph
We start by adding some data to our database. A few users and a few films ought to be made. Let's begin with our first query.
CREATE (john:User{firstName:"John"}), (tom:User{firstName:"Tom"}),
(mark:User{firstName:"Mark"})
CREATE (titanic:Movie{title:"Titanic"}),(avatar:Movie{title:"Avatar"}),
(forrest:Movie{title:"Forrest Gump"})
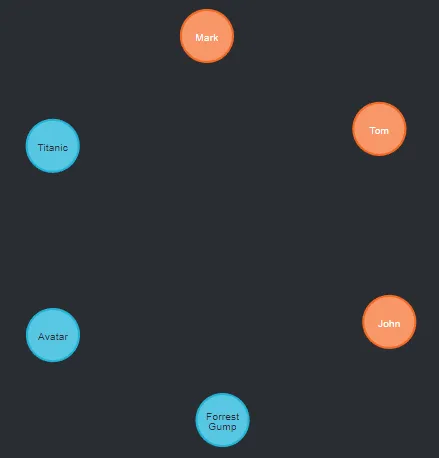
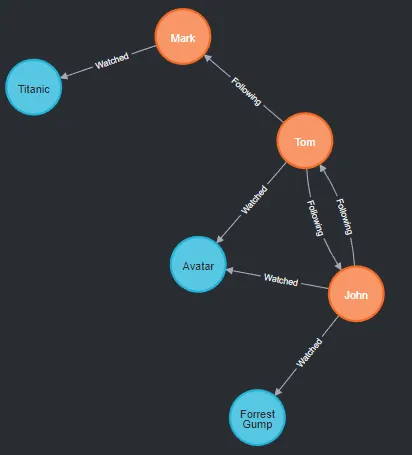
Now that our initial nodes have been successfully created, let's examine the graph. We must now add a few node-to-node relations. Start with Tom's favorite movies and the users that he follows.
# Create User -> Movie relationship called Watched
MATCH
(avatar:Movie{title: "Avatar"}),
(tom:User{firstName:"Tom"})
CREATE (tom)-[:Watched]->(avatar)
# Create user -> user relationship called Following
MATCH
(tom:User{firstName:"Tom"}),
(mark:User{firstName: "Mark"})
CREATE (tom)-[:Following]->(mark)
A few operations later, our final graph will look like this:
Let's make some queries
When our graph is filled with data, we can start exploring it. Let's begin with an easy task: finding all nodes with the label users.
MATCH (users:User)
return users
===================
RESULT
╒═══════════════════════════╕
│users │
╞═══════════════════════════╡
│(:User {firstName: "John"})│
├───────────────────────────┤
│(:User {firstName: "Tom"}) │
├───────────────────────────┤
│(:User {firstName: "Mark"})│
└───────────────────────────┘
Easy, right? Now, let's try to find all the movies that John watched.
MATCH (user:User{firstName:"John"})--(movies:Movie)
return movies
=========================
RESULT
╒════════════════════════════════╕
│movies │
╞════════════════════════════════╡
│(:Movie {title: "Avatar"}) │
├────────────────────────────────┤
│(:Movie {title: "Forrest Gump"})│
└────────────────────────────────┘
Okay, this one was a bit more challenging, but hopefully, you got the concept. Next, let's find all users followed by Tom.
MATCH (user:User)-[:Following]->(following)
WHERE ID(user) = 6
return following
==========================
╒═══════════════════════════╕
│following │
╞═══════════════════════════╡
│(:User {firstName: "John"})│
├───────────────────────────┤
│(:User {firstName: "Mark"})│
└───────────────────────────┘
As you can see, using Cypher is very similar to SQL. Our final task is to build a query for our recommendation system: finding all movies watched by users followed by Tom.
MATCH (tom:User{firstName: "Tom"})-[:Following]->(users)-[:Watched]->(movies)
return movies
==============================
RESULT
╒════════════════════════════════╕
│movies │
╞════════════════════════════════╡
│(:Movie {title: "Titanic"}) │
├────────────────────────────────┤
│(:Movie {title: "Avatar"}) │
├────────────────────────────────┤
│(:Movie {title: "Forrest Gump"})│
└────────────────────────────────┘
Almost there! One more thing to do: we need to exclude movies already watched by Tom. For that, we'll use the WHERE NOT clause.
MATCH
(tom:User{firstName: "Tom"}),
(tom)-[:Following]->(users)-[:Watched]->(otherMovies)
WHERE NOT (tom)-[:Watched]->(otherMovies)
return otherMovies
=================================
RESULT
╒════════════════════════════════╕
│otherMovies │
╞════════════════════════════════╡
│(:Movie {title: "Titanic"}) │
├────────────────────────────────┤
│(:Movie {title: "Forrest Gump"})│
└────────────────────────────────┘
Best practices for building your Neo4j recommendation system
Building a recommendation system with Neo4j offers powerful capabilities for creating personalized user experiences. The graph database structure naturally fits recommendation scenarios, making it easier to model complex relationships and query patterns.
Remember to:
- Start small: Begin with a simple graph before scaling.
- Monitor performance: Track accuracy and latency as data grows.
- Maintain data quality: Clean outdated or duplicated entries.
- Experiment: A/B test different algorithms and relationship weights.
- Gather feedback: Incorporate user responses to refine accuracy.
Neo4j supports popular languages like Python, Java, and JavaScript, making it easy to integrate your graph logic into web or mobile applications.
Final thoughts about Neo4j
Building a recommendation system with Neo4j lets you turn raw data into personalized experiences that drive engagement and retention. Start small, test often, and evolve your model as your user base grows.
At Kelltonn Europe, we help teams design and deploy intelligent systems that scale with business growth. Explore our Web Development services to see how we can help you build smarter digital products!
FAQ
What is Neo4j used for in recommendation systems?
Neo4j is a graph database that helps model relationships between users and items. It’s ideal for building recommendation systems because it stores and queries connections—like who watched or bought what—faster and more naturally than relational databases.
How does a recommendation system work in Neo4j?
A Neo4j-based recommendation system uses nodes (e.g., users, products) and relationships (e.g., “watched”, “liked”, “bought”) to analyze patterns. Using Cypher queries or graph algorithms, it can predict what a user might enjoy based on shared behaviors or attributes.
Is Neo4j better than SQL for recommendations?
Yes, for connected data. While SQL databases handle structured data well, Neo4j excels at traversing complex relationships in real time. This makes it more efficient for generating dynamic recommendations, such as similar users or related products.
Can Neo4j integrate with Python or Java?
Absolutely. Neo4j provides official drivers and APIs for popular programming languages like Python, Java, JavaScript, and Go, making it easy to integrate recommendation logic into web or mobile apps.


Sebastian Spiegel
Backend Development Director
Inspired by our insights? Let's connect!
You've read what we can do. Now let's turn our expertise into your project's success!